SMERF: Streamable Memory Efficient Radiance Fields for Real-Time Large-Scene Exploration
- Daniel Duckworth*1
- Peter Hedman*2
- Christian Reiser2,4
- Peter Zhizhin2
- Jean-François Thibert3
- Mario Lučić1
- Richard Szeliski2
- Jonathan T. Barron2
- Google DeepMind1
- Google Research2
- Google Inc.3
- Tübingen AI Center, University of Tübingen4
- equal contribution*





Abstract
Recent techniques for real-time view synthesis have rapidly advanced in fidelity and speed, and modern methods are capable of rendering near-photorealistic scenes at interactive frame rates. At the same time, a tension has arisen between explicit scene representations amenable to rasterization and neural fields built on ray marching, with state-of-the-art instances of the latter surpassing the former in quality while being prohibitively expensive for real-time applications. In this work, we introduce SMERF, a view synthesis approach that achieves state-of-the-art accuracy among real-time methods on large scenes with footprints up to 300 m^2 at a volumetric resolution of 3.5 mm^3. Our method is built upon two primary contributions: a hierarchical model partitioning scheme, which increases model capacity while constraining compute and memory consumption, and a distillation training strategy that simultaneously yields high fidelity and internal consistency. Our approach enables full six degrees of freedom (6DOF) navigation within a web browser and renders in real-time on commodity smartphones and laptops. Extensive experiments show that our method exceeds the current state-of-the-art in real-time novel view synthesis by 0.78 dB on standard benchmarks and 1.78 dB on large scenes, renders frames three orders of magnitude faster than state-of-the-art radiance field models, and achieves real-time performance across a wide variety of commodity devices, including smartphones.
Video
Real-Time Interactive Viewer Demos












How we boost representation power to handle large scenes
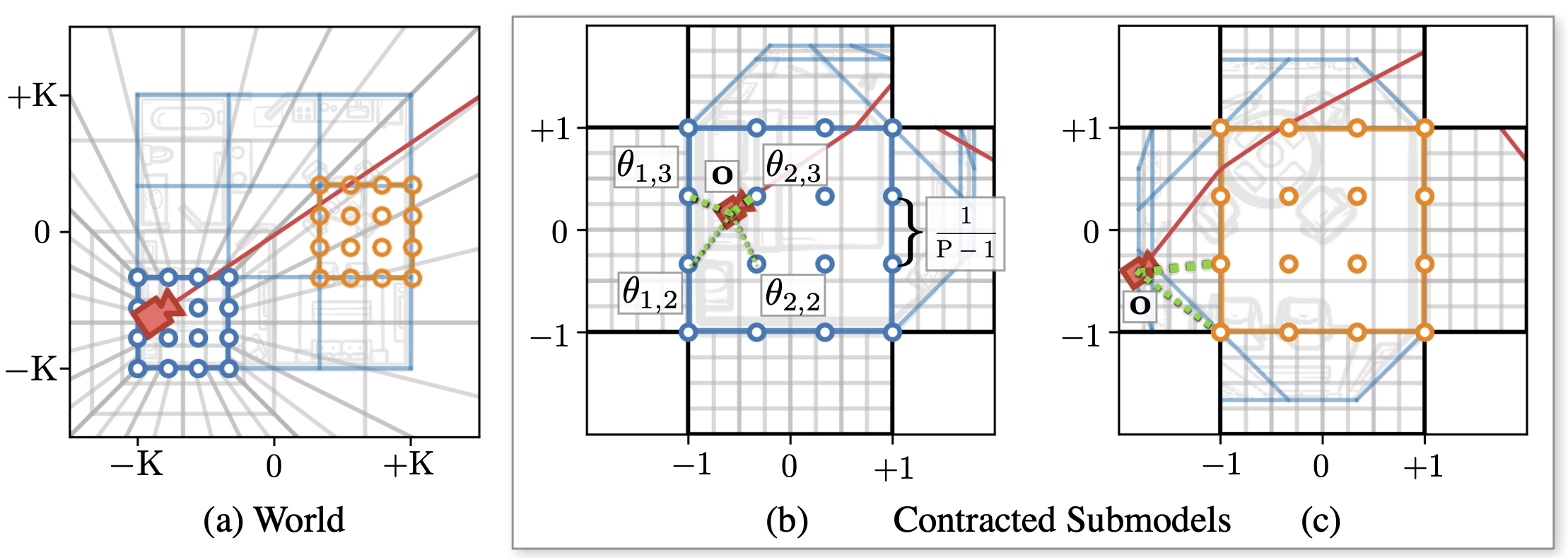
(a): We model large multi-room scenes with a number of independent submodels, each of which is assigned to a different region of the scene. During rendering the submodel is picked based on camera origin. (b): To model complex view-dependent effects, within each submodel we additionally instantiate grid-aligned copies of deferred MLP parameters \(\theta\). These parameters are trilinearly interpolated based on camera origin \(\mathbf{o}\). (c): While each submodel represents the entire scene, only the submodel's assiociated grid cell is modelled with high resolution, which is realized by contracting the submodel-specific local coordinates.
Getting the maximum out of our representation via distillation
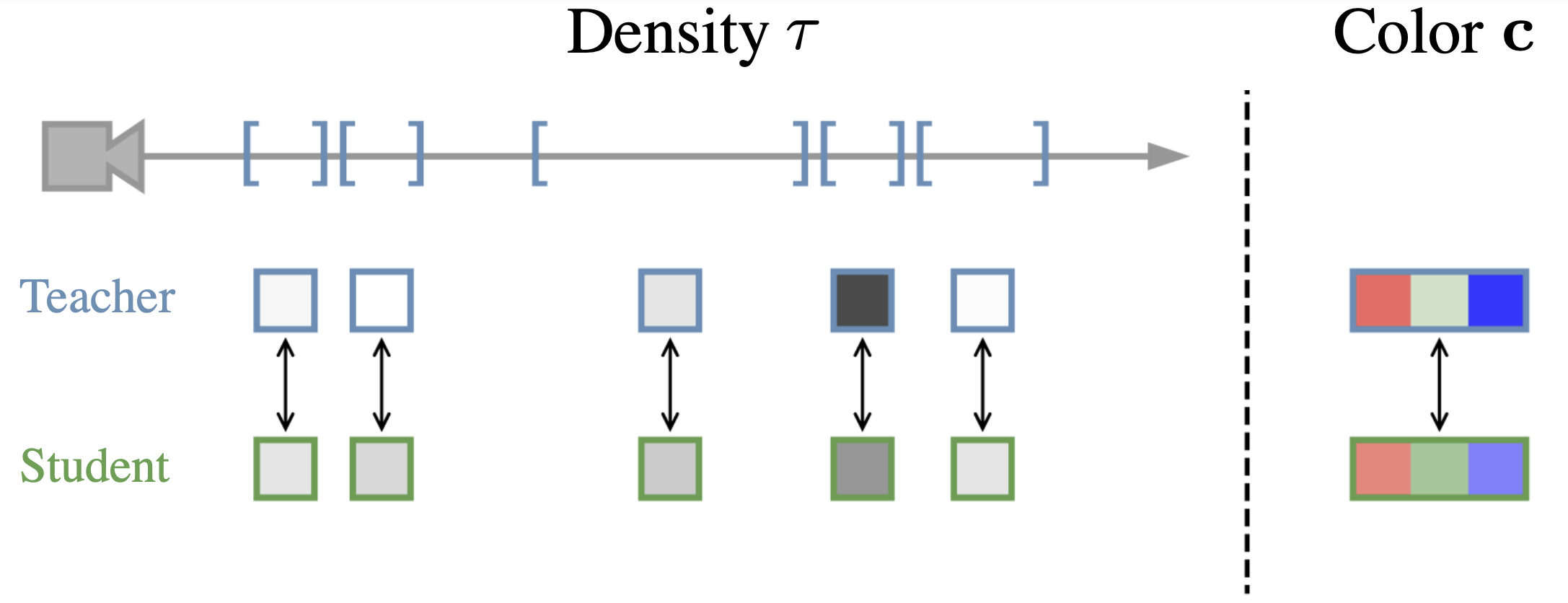
We demonstrate that image fidelity can be greatly boosted via distillation. We first train a state-of-the-art offline radiance field (Zip-NeRF). We then use the RGB color predictions \(\mathbf{c}\) of this teacher model as supervision for our own model. Additionally, we access the volumetric density values \(\tau\) of the pre-trained teacher by minimizing the discrepancy of volume rendering weights between teacher and student.
Datasets & Teacher Checkpoints
SMERF models are distilled from Zip-NeRF checkpoints trained on the Mip-NeRF 360 and Zip-NeRF scenes. The checkpoints below are used to recreate the quantitative results in the published text. Both datasets and checkpoints are released under CC-BY 4.0 license. See text for additional details.
| Photos | Teacher Checkpoints | Notes | |
|---|---|---|---|
| Mip-NeRF 360 | Project website | Download All | For quantitative and qualitative results. Zip-NeRF checkpoints are trained for 50,000 steps. Checkpoints for treehill and flower available upon request. |
| Zip-NeRF (fisheye) | Alameda, Berlin, London, NYC | Download All | For qualitative results. Zip-NeRF checkpoints are trained for 100,000 step. |
| Zip-NeRF (undistorted) | Alameda, Berlin, London, NYC | Download All | For quantitative results. Zip-NeRF checkpoints are trained for 100,000 steps. |
Citation
If you want to cite our work, please use:
@misc{duckworth2023smerf,
title={SMERF: Streamable Memory Efficient Radiance Fields for Real-Time Large-Scene Exploration},
author={Daniel Duckworth and Peter Hedman and Christian Reiser and Peter Zhizhin and Jean-François Thibert and Mario Lučić and Richard Szeliski and Jonathan T. Barron},
year={2023},
eprint={2312.07541},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Acknowledgements
The website template was borrowed from Michaël Gharbi. Image sliders are based on dics.